diffusersでStableDiffusionXLモデルのAnimagineXL3.1とControlNetのOpenposeを組み合わせてローカル環境で画像生成してみる【Python】
前回はAnimagine XL 3.1のサンプルコードを動かしてみましたが、今回はControlNetのOpenposeと組み合わせてみます。
概要
ControlNetについて
ControlNetは、追加条件を追加して拡散モデルを制御するニューラルネットワーク構造です・・・というと何だかよくわかりませんが、簡単にいってしまえば「AI画像生成の補助機能」です。
例を見てしまった方が早いので、以下で見ていきましょう。
例
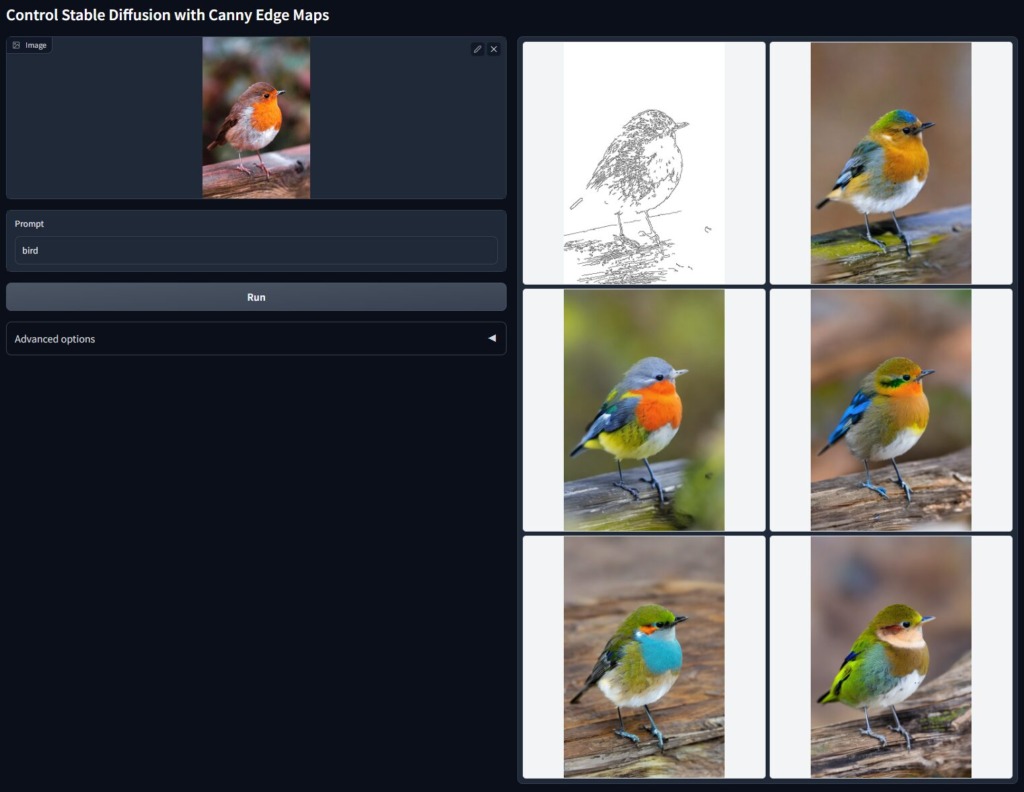
Canny Edge
Canny Edgeではエッジ検出によって、画像を再生成することができます。
左の元画像に対して、右の白い画像がCanny Edgeで生成された画像、さらに残り5枚がその画像からさらに生成された画像です。
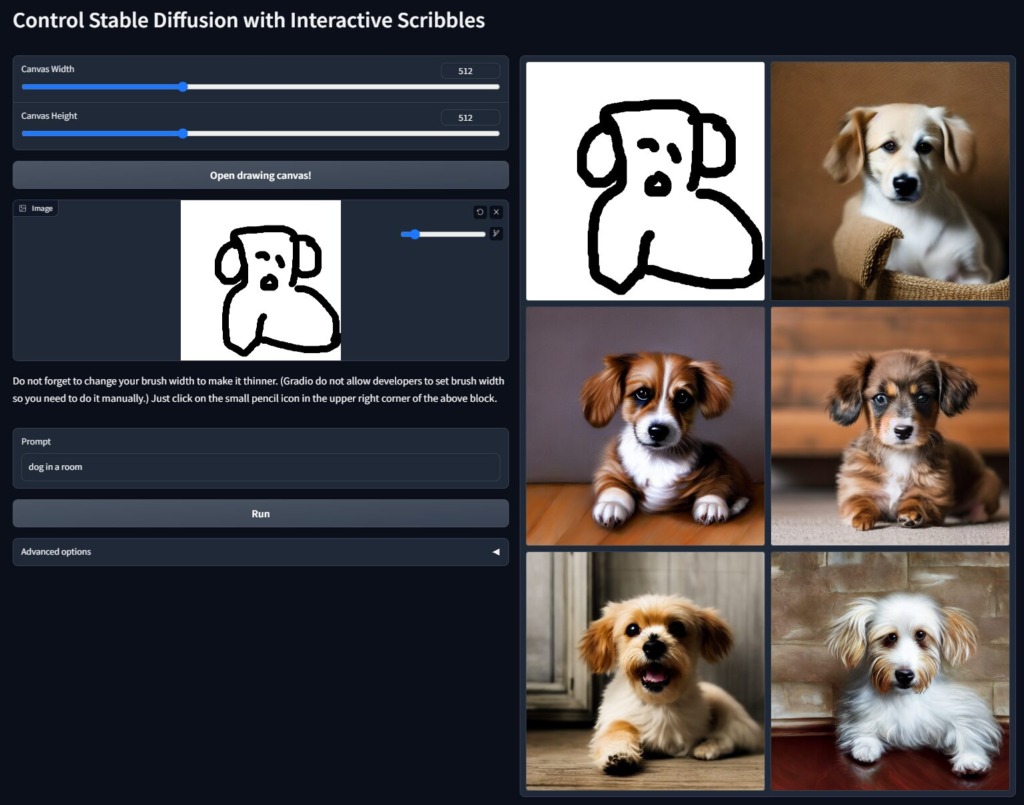
Interactive Scribbles
Interactive Scribblesでは、こんな落書きからも特徴を抽出してクオリティの高い画像が生成できます。
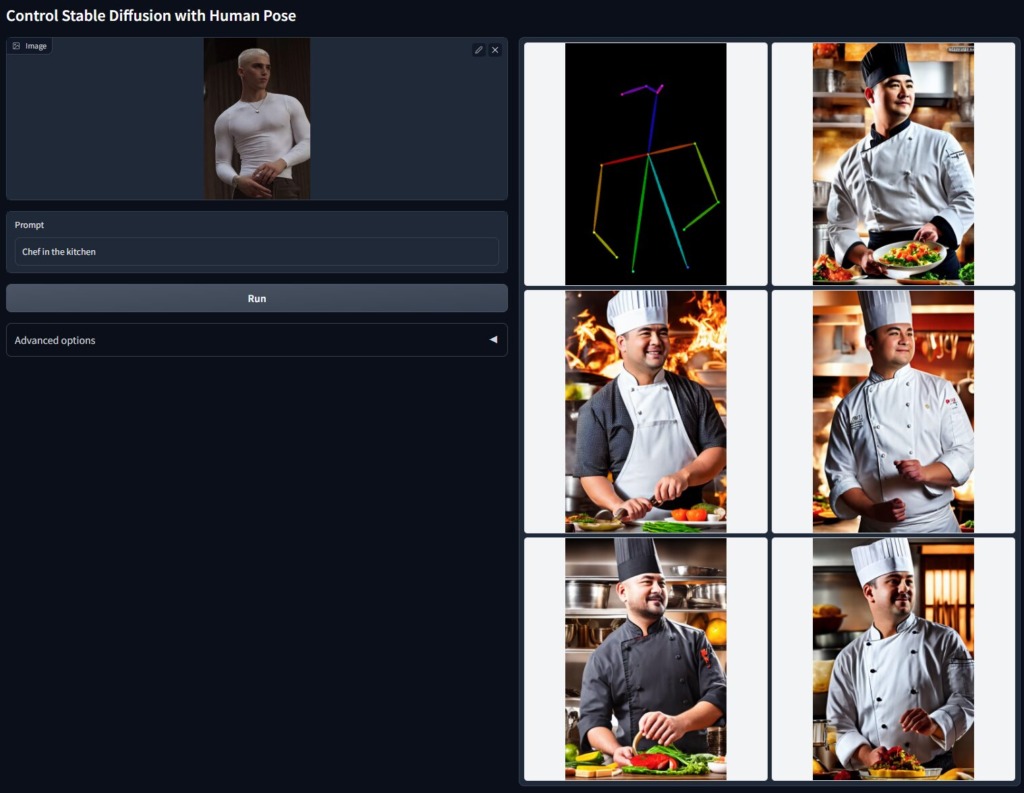
Human Pose (Openpose)
Openposeでは、ポーズを抽出することで、同じポーズの画像を生成できます。
画像生成
今回はOpenposeを使用して画像生成してみます。
使用するコード
import torch
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel
from diffusers.utils import load_image
from controlnet_aux import OpenposeDetector
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(image)
controlnet = ControlNetModel.from_pretrained(
"thibaud/controlnet-openpose-sdxl-1.0",
torch_dtype=torch.float16
)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"cagliostrolab/animagine-xl-3.1",
torch_dtype=torch.float16,
use_safetensors=True,
controlnet=controlnet,
)
pipe.to('cuda')
prompt = "1girl, souryuu asuka langley, neon genesis evangelion, solo, upper body, v, smile, looking at viewer, outdoors, night"
negative_prompt = "nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]"
image = pipe(
prompt,
negative_prompt=negative_prompt,
width=832,
height=1216,
guidance_scale=7,
num_inference_steps=28,
image=openpose_image,
controlnet_conditioning_scale=0.6,
).images[0]
image.save("./result/asuka_test.png")前回のサンプルコードを基に、Openposeを組み込んでみました。
Openpose使用にあたっては、StableDiffusionXLControlNetPipelineを使用します。
前回使用したDiffusionPipelineでは動作しませんので、ご注意ください。
ちなみに、StableDiffusionXLモデルはStableDiffusionXLControlNetPipeline、StableDiffusionモデルはStableDiffusionControlNetPipelineを使用します。
簡単な解説
以下のコードでは、ポーズ変換してくれるモデルを使用して、サンプル画像(ポケットに手を突っ込んで立っているおっさん)のポーズを読み込み、ポーズ画像を生成しています。
読み込む画像はURLではなくローカルでもOKです。
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(image)
以下では、ControlNetのOpenpose用のモデルを読み込んで、パイプラインに渡しています。
今回はSDモデルではなくSDXLモデルを使用するため、OpenposeもSDXLモデルを設定します。
controlnet = ControlNetModel.from_pretrained(
"thibaud/controlnet-openpose-sdxl-1.0", # SDXLモデル
torch_dtype=torch.float16
)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"cagliostrolab/animagine-xl-3.1", # SDXLモデル
torch_dtype=torch.float16,
use_safetensors=True,
controlnet=controlnet,
)以下では、前回同様にパラメータを設定していますが、特筆すべきはimageとcontrolnet_conditioning_scaleです。
imageで先ほど生成したポーズ画像を引き渡し、controlnet_conditioning_scaleでどれくらいポーズを再現するのかを指定しています。
controlnet_conditioning_scaleは0~1.0で指定し、1に近いほど再現率が高くなります。今回は0.6なので、そこそこ再現する程度です。
image = pipe(
prompt,
negative_prompt=negative_prompt,
width=832,
height=1216,
guidance_scale=7,
num_inference_steps=28,
image=openpose_image,
controlnet_conditioning_scale=0.6,
).images[0]結果
かなり良い結果が得られました。
Openposeで読み込んだおっさんのポーズを6割再現するという指示通りで、かなりクオリティも高く仕上がっていると思います。
ちなみに、controlnet_conditioning_scale=1.0を指定してしまうと、こんな感じになります。
う~ん、、キモいですね。
恐らくですが、AnimagineXL3.1の良さを損ねるくらいにOpenposeが幅を利かせているからなのかなと思います。
実用面を考えれば、controlnet_conditioning_scale=0.6前後が妥当かなというのが個人的な感覚です。
以上です。
【Reference】